
Escaping the Trifecta
So you’ve read Simon Willison’s post about the lethal trifecta and how, like the infinity stones on Thanos’ gauntlet, you really don’t want them all to be present at once.
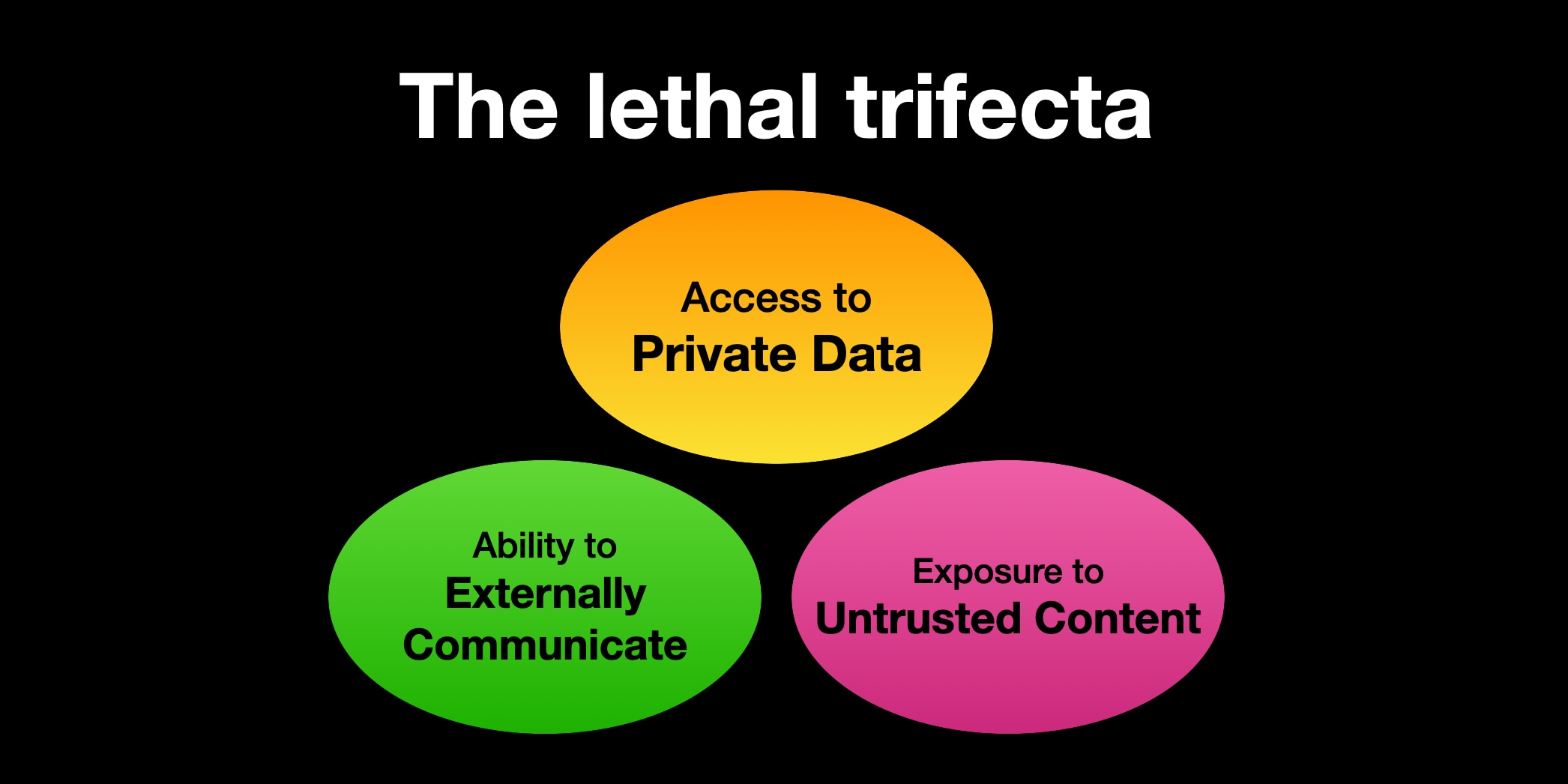
Now you’re wondering how much utility you can squeeze out of your AI agent without ever exceeding two of the three trifecta legs.
Every time a new bug ticket is escalated, your AI agent living in the cloud is triggered and is tasked with solving the problem, typically in the form of a pull request.
Two things you realise:
- It’s hard to solve production issues without access to production data
- It’s hard to solve production issues involving external systems without the ability to google things about those systems (e.g. ‘what does this error mean?’)
Unfortunately, both production data AND google results can contain untrusted content. Production data is certainly private, and googling requires the ability to externally communicate.
So it’s not possible to have both production data access and general internet access without completing the trifecta.
Which do you choose to keep? Arguably whatever your agent might want to google is likely in its training set already, so perhaps it’s better to prioritise access to production data.
But do you need to choose? What if your agent had two phases: a research phase and an execution phase. In the research phase the agent does all the googling it wants, no matter how many prompt injection attempts are thrown at it. But as soon as it wants to query your production data, the googling ability is removed. So you never have all three legs of the trifecta in play at any one time.

One annoying implication of this approach is that if the agent actually does want to go back and do some more googling after looking at the production data, it will need to rope in a human to review its context and approve the phase reset.
The good news is that AI agents already need a couple rounds of human feedback anyway even without internet access, so it’s not too much to ask for a little more human feedback in exchange for a stronger security posture.
What’s crazy is that for many companies, AI is now sufficiently advanced that intelligence isn’t the bottleneck: privileges are. And like the Little Shop of Horrors, how much are you willing to feed it?
Other things to note:
- The original bug ticket may itself contain private data, meaning you’ve already completed the trifecta by the research phase. But a human is the one to escalate the ticket meaning the human can remove any confidential / sensitive information beforehand.
- The codebase that your agent has access to is also private data. You might decide that the codebase is actually not that sensitive compared to production data and allow the research phase to access it, or you might only grant access to the execution phase.
- We’re assuming that you’ve locked down everything else e.g. you’re cool with the LLM itself having access to production data etc.
Shameless plug (which appears on every blog post, not just this one, so don't think that I'm opportunistically posting this specific post just for the sake of doing this plug): I recently quit my job to co-found Subble, a web app that helps you manage your company's SaaS software licences. Your company is almost certainly wasting time and money on shadow IT and unused/overprovisioned licences and Subble can fix that. Check it out at subble.com